1. Data Modeling이란?
- 주어진 개념으로부터 논리적인 모델을 구성하고, 이를 물리적인 모델로 표현하는 것을 말한다.
- 업무를 분석하여 일정한 표기법으로 표현하여 데이터베이스를 만들고, 개발 및 데이터관리에 사용하기 위한 것이다.

- 3요소
- Entity(엔터티) → Table
- Relation(관계) → PK, FK
- Attribute(속성) → Column
- 특징
- 추상화 : 현실을 일정한 형식에 맞추어 표현한다.
- 단순화 : 누구나 쉽게 이해할 수 있도록 표현한다.
- 명확화 : 애매모호함을 제거하고 유일한 의미를 갖도록 표현한다.
- 관점
- 데이터 관점 : 업무와 데이터의 관계, 또는 데이터 간의 관계는 무엇인지에 대해서 모델링하는 방법.
- 프로세스 관점 : 무엇을 하고 있는지, 또는 무엇을 해야 하는지를 모델링하는 방법.
- 데이터와 프로세스의 상관관점 : 업무에 따라 데이터는 어떤 영향을 받는지를 모델링하는 방법.
- 기능
- 시스템을 현재 또는 원하는 모습으로 가시화하도록 도와준다.
- 시스템의 구조와 행동을 명세화 할 수 있게 한다.
- 시스템을 구축하는 구조화된 틀을 제공한다.
- 시스템을 구축화는 과정에서 결정한 것을 문서화한다.
- 다양한 영역에 집중하기 위해 다른 영역의 세부 사항은 숨기는 다양한 관점을 제공한다.
- 특정 목표에 따라 구체화된 상세 수준의 표현방법을 제공한다.
2. Data Modeling의 순서
- 개념적 데이터 모델링 : 핵심 엔터티를 통해 관계를 발견, ERD(Entity-Relation Diagram)을 생성하는 것.
추상적인 모델로 상위의 문제에 대한 구조화를 쉽게 해주며, 사용자와 개발자가 기능에 대해 논의할 수 있는 기반을 형성한다. - 논리적 데이터 모델링 : 물리적 스키마를 설계하기 전 최종적으로 완료된 상태.
식별자 확정, 정규화, M:N 관계 해소, 참조 무결성 규칙 정의, 이력 관리 전략 정의 등이 완료된 상태이다. - 물리적 데이터 모델링 : 테이블, 칼럼 등으로 표현되는 저장 구조와, 저장 장치, 접근 방법 등이 결정된 상태.
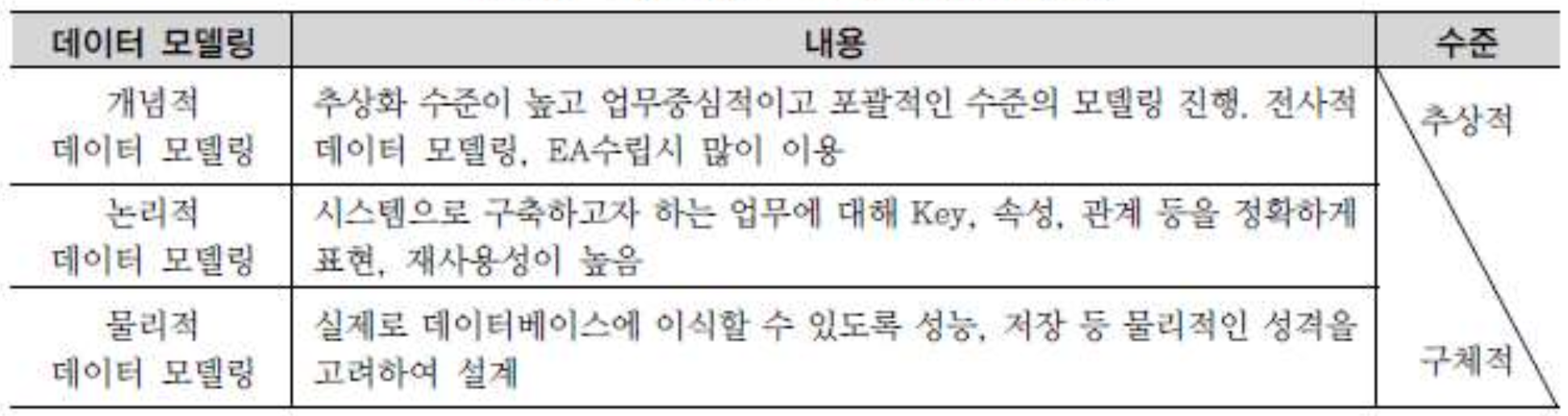
3. Data Modeling의 중요성과 유의점
- 중요성
- 파급효과 : 구축된 데이터 구조의 변경은 전체 시스템에 영향을 미친다.
- 간결한 표현 : 구축할 시스템의 요구사항과 한계를 가장 명확하고 간결하게 표현할 수 있는 도구이다.
- 데이터 품질 : 축적된 데이터는 비즈니스에 전략적으로 활용할 가치를 지닌다.
- 유의점
- 중복(Duplication) : 데이터의 중복은 그 자체로 데이터의 품질을 악화시킨다.
- 비유연성(Inflexibiility) : 유연하지 못한 데이터 모델은 유지보수에 어려움을 겪는다.
- 비일관성(inconsistency) : 데이터 간의 상호 연관관계에 대한 명확한 정의가 있어야 한다.
4. Data Modeling의 지향점
- 완전성 : 필요로 하는 모든 데이터가 데이터 모델에 정의되어야 한다.
- 중복배제 : 동일한 사실은 반드시 한 번만 기록되어야 한다.
- 업무규칙 : 모델링 과정에서 도출되는 수많은 규칙을 표현하고 공유 가능하게 제공해야 한다.
- 재사용 : 웬만한 업무 변화에도 데이터 모델이 영향을 받지 않고 운용될 수 있어야 한다.
- 의사소통 : 관련자들이 업무 규칙들을 동일한 의미로 받아들이고 정보시스템을 활용할 수 있어야 한다.
- 통합성 : 공유 데이터에 대한 구조를 여러 업무 영역에서 공동으로 사용 가능해야 한다.
반응형
'DATABASE > CONCEPT' 카테고리의 다른 글
| [DB] 반정규화 (De-Normalization) (0) | 2023.02.27 |
|---|---|
| [DB] Attribute (0) | 2023.02.26 |
| [DB] Relationship (0) | 2023.02.25 |
| [DB] Entity (0) | 2023.02.24 |
| [DB] 정규화 (Normalization) (0) | 2023.02.12 |




댓글